
Ok, In Part 3 and Part 4, now outlined two concepts:
- Knowledge flywheels
- Rate of learning by humans, as an operating activity and marathon.
Now the goal is to put this together to look at rate of learning by machines.
Recall, the Input and Output KPIs for Rate of Learning by Humans
In Part 3, I outlined how rate of leaning by humans historically gets shown as a learning curve, which is:
“a graphical representation of the relationship between proficiency and experience”
Such as these:

That’s how I think about rate of learning by humans. And by humans using digital tools. Individually, in teams, in enterprises and across industries.
And this is a good framework for comparison because how humans learn is pretty understandable.
I also outlined the inputs and outputs that matter. The x and y axis of the below graphic have the KPIs for human learning you can track.

On the x axis, we can see the experience inputs that usually matter:
- Cumulative and/or concurrent volume of the task or product.
- Cumulative time spent.
On the y axis, we can see the proficiency outputs that usually matter:
- Increasing efficiency of a task completed, or of a created product. We want to see decreasing cost and / or time spent on a particular process. Or for completing a product.
- Increasing quality and/or performance of a task or product. The task should have fewer errors. The product should be higher quality.
- Advancements or improvements over time. We want to see new and improved products launched. We want to see significant upgrades to work processes.
Those are typically the KPIs that matter for rate of learning by humans. And if we chart them, we can start to see the shape of the learning curve.
In my books, I cited two common types of learning by humans (most of this was BCG thinking). There was:
- Cost-Focused Rate of Learning. Think aviation assembly and building Model T cars.

- Product-Focused Rate of Learning. Think Steve Jobs. He was good at learning about changing technology and consumer behavior – and quickly and cost-effectively launching new products.

Ok. Now let’s try to extend all this to Rate of Learning by machines (i.e., machine learning).
How Machine Learning Is Different
First question:
Do machines, like humans, learn and become more proficient based on cumulative experience?
This was the core assumption of the previous framework. That for humans “practice makes perfect”.
And this is definitely a significant driver for machine learning. But is it the biggest driver of increasing proficiency in machine learning? Think about this:
- Is proficiency mostly about the number of times a task or process has been done cumulatively?
- It is mostly about the number of units produced over time?
- Like producing lots of one type of car?
- Is proficiency mostly about the number of times a task or process is being done concurrently?
- Is it about real time production? Such as the units produced per hour?
- Is proficiency about the time spent on an activity?
- Is there a Malcolm Gladwell 10,000-hour rule for machines?
For machine learning, I don’t think so.
Cumulative production can definitely be a factor. But I don’t think this is the primary driver for machine proficiency in most cases. I think the x axis of the learning curve is completely different for machines vs. humans.
Another question:
Do machines learn and become more proficient based on the volume of relevant data they access and process?
Recall from Baidu (I added the bold):
“The (ERNIE) model learns from large-scale knowledge maps and massive unstructured data, resulting in more efficient learning with strong interpretability.”
Is access to massive amounts of relevant data the biggest driver of proficiency?
I think massive unstructured data access is definitely in the top 3.
And what exactly is relevant data? Is it from users and their engagement? Is it passive data from cameras and IoT devices?
Also, is this cumulative or real-time data?
Keep in mind, foundation models are not storing its massive amounts of data. They are ingesting massive amounts of data in real-time and then doing processing. The data architecture is a big part of effective learning.
So, is it about data access or data processing capabilities? That’s a good question.
Another question:
Do machines learn and become more proficient based on the scale of their computing power?
Is it about the access to big data volume or about having the computing power to process it? The big assumption of the past two years has been that intelligence increases with scale. The more Nvidia chips you have the better your system.
Another question:
Is this about the advancing quality of a knowledge map over time?
Keep in mind, the data processing happens within advancing knowledge maps.
Again from Baidu (I added the bold):
“The (ERNIE) model learns from large-scale knowledge maps and massive unstructured data, resulting in more efficient learning with strong interpretability.”
But do these knowledge maps become better and better over time? Like with a relatively fixed set of knowledge like science and law.
Or do they become obsolete and must continually adapt? Like with traffic maps and what someone wants to watch next on TikTok?
Last question:
Where does learning and advancing proficiency by machines require the involvement of humans?
Are we talking about data or user engagement? Do we need humans in the loop?
Ok. Let’s jump to the KPIs.
Input and Output KPIs for Rate of Learning by Machines
Based on all that, here are the input and output KPIs I use for rate of learning by machines.

On the x axis, we are looking for industrial applications as inputs:
- Users and their engagement is important for many areas. We definitely need this for relevance (what video I want to watch next). We also need this for human created content (like videos and such).
- Relevant data is important and can come from humans or passively (cameras, databases, etc.).
- Knowledge maps are key. They can be built internally or accessed and/or customized from larger models.
For the y axis, we are looking for knowledge enhancement outputs:
- We want to see improved knowledge or accuracy. This is key for topics that are largely set knowledge, such as the law, science and mathematics. Accuracy is about getting you a correct and accurate answer.
- In some cases, we want to see relevance and adaptability. In other topics, the “right answer” can change over time. Such as the traffic patterns in a city day by day. That would be adaptability. Or what video I want to watch next (which would be relevance or preference). Or what answer by customer service puts me in a good emotional state (i.e., I was angry and now I’m not). This is about adapting knowledge and ranking preferences over time. It can also be about choosing the answer that is most relevant for someone.
- Increasing efficiency. This is mostly decreasing cost and speed / latency. Cost is a big deal in these big models.
Those are the outputs KPIs I look for. And that lets you chart out the shape of the learning curve. And if you can’t actually graph it, you want get a sense of the relationship between the two variables. You want to identify the mechanisms by which they change.
Ok. Hold that thought for a moment.
Operational Flywheels Are Usually Short-Term Phenomenon
In Part 2, I talked about how machine learning can have a knowledge flywheel (You Need to Understand Generative AI Knowledge Flywheels). And that relates to this subject of rate of learning.
Flywheels are a phenomenon within an operating model. So I call them operational flywheels. It’s when two or more operating activities improve each other reflexively.
- Operating activity A makes operating activity B cheaper, faster or better. Such as using data to improve the customer experience.
- And then operating activity B makes A cheaper, faster or better. Such as when the improved customer experience causes more usage and therefore generates even more data.
- Which then repeats the cycle.
That is an operational flywheel that is often (mistakenly) called a data network effect. But we are talking about a phenomenon within an operating model. Not a network effect.
I generally look for operational flywheels to do one of four things:
- To improve the product or service.
- That’s the “data network effect” idea described. It’s a flywheel that results in a better product. Usually with an increased rate of product improvement.
- To accelerate growth.
- Often the flywheel will involve a sales or marketing function. And can impact customer acquisition or sales. So the flywheel accelerates growth.
- To improve operating performance.
- It makes something operationally cheaper, faster or better. Say the functioning of the factory. Or the performance of a machine learning function.
- To create a superior key asset or capability.
- That’s a more strategic sub-version of 3. It’s great to have a flywheel in a strategic operating asset or capability.
For machine learning flywheels, we are really talking about 2 and 3.
We are looking for a big effect on growth and performance (usually intelligence). That’s what people are talking about with regards to the machine learning flywheel.
However…
Just because you grow faster or have a superior product now, does not mean it will last. You might have had an operating flywheel that enabled you to create a French-English translator faster or cheaper than others. But eventually everyone will have that. Flywheels are usually an operating phenomenon in the short-term.
Ok. So how does this relate to machine learning curves.
Flywheels Accelerate Learning. But It is the Shape of the Learning Curve that Matters Most.
For superior operating performance (or product improvement) in the long-term, you want to look at the shape of the learning curve.
Does proficiency keep increasing with more experience?
Does it flatline quickly? Like with a French-English translator.
Here’s how I think about operating flywheels and machine learning curves.

Flywheels are great. And they can be important in accelerating parts of the curve. But they don’t change the ultimate shape. And the shape of the curve determines your ultimate competitive strength.
- Did you just build a commodity capability faster than others?
- Or do you have an ongoing intelligence advantage?
That is the difference between an operating activity that is required (i.e., table stakes) versus one that can create a sustainable advantage.
Last Point: Rate of Learning by Machines Will Become Operating Table Stakes for Most Companies
Rate of learning by humans was kind of a niche, interesting topic in strategy. It mattered a lot for certain companies like Toyota and TSMC.
However, rate of learning by machines is becoming part of operating performance for most companies. It is part of the AI core for management and operations (DOB3). In the long-term, businesses are becoming intelligent.
In my books, I talked about Algorithmic Learning (mostly a BCG idea).
This is when the rate of learning and adaptation is no longer based on human learning (people looking at data and making decisions) but is instead based on learning by machines. So, sensors, cameras, computers, and AI are all handling real-time analysis and making automated decisions.
For example:
- Webpages, mobile apps, cameras, IoT devices, and other sensors are gathering data all the time. Computers no longer rely on humans or other computers for information. They can increasingly “see” the world for themselves via cameras, sensors, microphones, and web-crawlers. They are now continually gathering information about the physical and online worlds independent of human operators. Hence the term, computer vision.
- They can combine real-time events and information flows with past information and accumulated information.
- They can then make immediate predictions and recommendations, which is what AI does. They can also increasingly make the decisions as well. This is how a Tesla drives down the highway at 65mph without human involvement. The car is learning at the speed of algorithms and then making its own decisions.
Basically, the first version of rate of learning by machines is about moving learning to a much faster time scale.
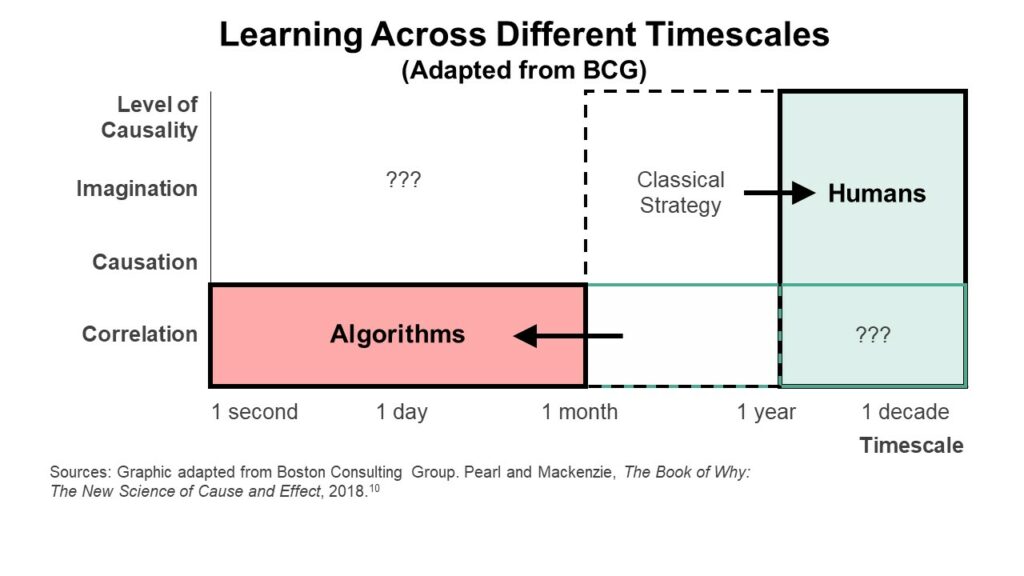
When I talk about rate of learning as a digital marathon, I am mostly talking about algorithmic learning. This is when certain companies are operating and adapting at a speed that is baffling to non-digital competitors.
For example, most traditional retailers are still doing weekly inventory checks, making occasional price changes, and changing their merchandising mix every couple of weeks. Competitors like Amazon and Shein can change their inventory and prices every second based on real-time feedback. If it starts raining in one part of town, local stores can start raising and dropping certain product prices in seconds.
This creates an interesting view of competitive strategy.
- You still need to think about competing over years. This is when you make longer-term and often irreversible decisions as a company. Think entering new countries, developing oil fields, building refineries, and developing the next major Boeing plane. This is usually the purview of top-down strategy. Most of my thinking about moats and marathons is in this area.
- You need to think about competing over weeks and months. Think Coca-Cola versus Pepsi doing marketing in India. Or rapid new product introductions. This is usually about tactical moves, operating decisions, and product launches.
- You now need to start thinking about competing in seconds and milli-seconds. Software can gather data, learn, and make decisions at the speed of algorithms. This can happen in assets like factories, in the functionality and user experience with products and services and in company-wide operations.
Digital businesses need to focus much more on rate of learning and adaptation, which usually also means lots of innovation and experimentation. It’s a key part of operating performance.
That’s really the first version of all this.
***
Ok. that’s it for the theory. And I know this was a lot.
In Part 6, I’m going to boil this down into a useable GenAI strategy.
Cheers, Jeff
——-
Related articles:
- AutoGPT and Other Tech I Am Super Excited About (Tech Strategy – Podcast 162)
- AutoGPT: The Rise of Digital Agents and Non-Human Platforms & Business Models (Tech Strategy – Podcast 163)
- The Winners and Losers in ChatGPT (Tech Strategy – Daily Article)
From the Concept Library, concepts for this article are:
- Learning Curves and Experience Effect
- Operational Flywheels
- GenAI and Agentic Strategy
- GenAI Playbook
From the Company Library, companies for this article are:
- n/a
——-
I am a consultant & keynote speaker on how to increase digital growth and strengthen digital AI moats.
I am the founder of TechMoat Consulting, a consulting firm specialized in increasing digital growth and strengthening digital AI moats. Get in contact here.
I write (a lot) about digital growth and digital AI strategy (3 best selling books, +2.9M followers on LinkedIn). There is a free book and email newsletter below.
My Moats and Marathons book series is a framework for building and measuring competitive advantages in digital businesses.
This content (articles, podcasts, website info) is not investment, legal or tax advice. The information and opinions from me and any guests may be incorrect. The numbers and information may be wrong. The views expressed may no longer be relevant or accurate. This is not investment advice. Investing is risky. Do your own research.