
In Parts 1-3, I mostly went through AI infrastructure. The advancements in GPUs, servers and interconnect. Important but technical.
In this article, I want to shift more to business takeaways, specifically cloud services and data management. And that is what businesspeople are dealing with in GenAI and agents.
In Barcelona, I went to the Huawei Cloud Summit, which was in the mountains above the city. It was pretty amazing. Barcelona just has the best geography. Both beaches and mountains. And a beautiful historic city between them.
Here are photos from the Summit (and of Barcelona).





Huawei Cloud’s Pitch for the Global Market: AI Infrastructure and Enterprise-Grade Agents
The new CEO of Huawei Cloud is Peter Zhou. So, he is on the front lines of deploying AI apps and cloud services. He announced that Huawei’s public cloud business has seen a big increase outside China.
That’s really interesting.
That’s a number I watch for Huawei Cloud (as well as for Alibaba Cloud and Tencent Cloud. Baidu Cloud is staying mostly in China). I’m watching the adoption rates of these platforms outside of China.
Peter described their international growth strategy as:
- Providing better products – mostly by putting AI in them.
- AI coding and agent tools are a big focus here. I’ll talk about that in the next article.
- Providing more resources to the local service teams.
- This is about supporting sales and also supporting their growing ecosystem, which go hand in hand.
- That means lots of partner support. And conferences and training.
Another speaker at the summit who caught my attention was Tim Tao, President of Solution Sales.
He argued that enterprises are moving from focusing on “AI compute” to “AI capabilities”. Which means shifting the focus from LLMs and infrastructure scale to using agents and tokens within your business.
Ok. I buy that.
But I was trying to clarify the specific Huawei Cloud pitch. How does it differentiate from international competitors like AWS and Google Cloud?
From the talks, here is my working answer to that question. They are providing:
- AI Infrastructure and full stack AI cloud services..
- Industry models that are “open source”. I discussed this in Part 2. That is a compelling strategic move. The wave of open-source models and AI architecture coming out of China has really forced Silicon Valley to respond.
- Agent operations that are “enterprise grade”. They use the phrase enterprise-grade a lot, especially in their data platforms. It appears to be their quality standard. I think they are thinking industry verticals. And professional (not consumer) clients. Maybe.
Tim had an interesting point where he mentioned that 95% of data is not public. It is within industries and enterprises. And similarly, while 90% of general tools are available through APIs, only 20% of enterprise systems are available through APIs.
The argument is that industry capabilities and data are what is currently setting the upper limit on the performance of AI applications.

Which brings me to the focus of this article. Which is how inference, data management and knowledge bases in enterprises is taking center stage.
The Next Phase: The Shift from AI Training to Scalable Inference
In Part 1, I talked about how Huawei is focusing on heterogenous computing in their AI data centers. They don’t rely on one powerful chip (like NVIDIA Blackwell). They use combinations. Some are specialized for high-powered model training and some are focused on fast, efficient inference .
That’s important because we can see the workloads shifting to AI inference. Here is some data from McKinsey & Co on this. They predict that inference workloads will surpass training workloads by 2030. It will become 30-40% of total data center demand.
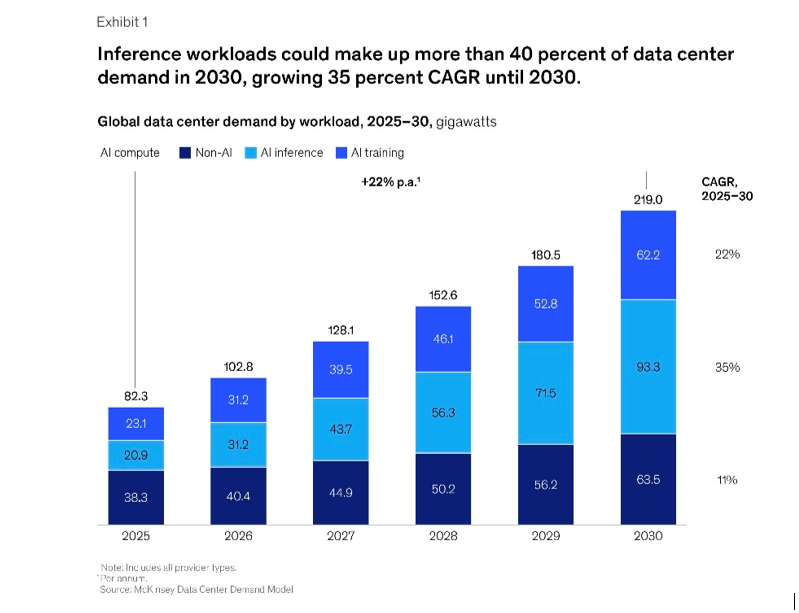
That means cloud services are shifting from one-time model training to sustained inference activity. Which means speed, efficiency and continuity of service are going to be increasingly important.
Here is a good summary (also McKinsey) of how cloud data centers are evolving into a mixture of traditional compute, training and inference. Which have very different capabilities and requirements.
How do you balance power and performance hungry training workloads with high-availability, low-latency inference workloads?
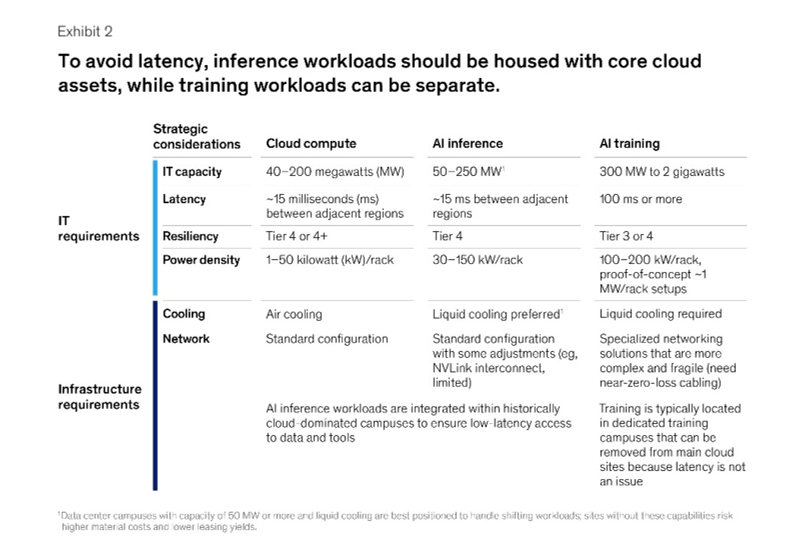
This shift towards inference has lots of implications for cloud services. If you want to reduce latency, you need data centers close to metropolitan areas. And you want the workloads co-located with applications and storage.
You also need to think about how these inference workloads can surge in demand. There can be tremendous volatility in inference activity that we don’t see in training. It is far less predictable and you need lots of flexibility and back-ups. And this includes flexibility and reserve capacity in the power supply systems. That compounds the already difficult challenge of power requirements in AI data centers, which require far more power than traditional data centers.
Why AI Performance is Now a Knowledge, Data and Memory Management Problem
Here is Tim Tao’s slide on the AI tech stack. And right above the infrastructure layer is data. But really what we are talking about is “AI Ready Data”. That is data that has been processed, cleaned, labeled, and stored such that it can be used rapidly and accurately when it is fed to models.
It also includes the knowledge base, which is used in RAG.
And it includes memory, which can be on chip, circuit board and servers.
There is a lot going on in that particular layer of the AI tech stack.

Thomas Meyer, Senior Vice President and General Manager of IDC Worldwide Research, also had a good slide about how much data generation and storage is growing.
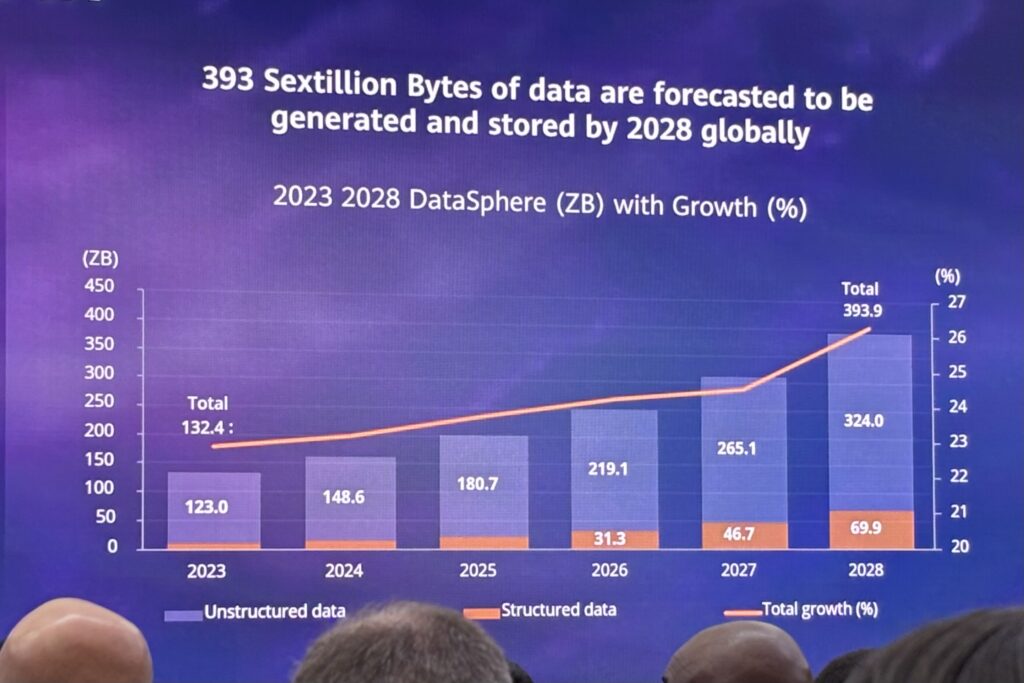
This raises an important question for virtually every CEO trying to use AI tools and agents.
How do you organize your growing data so it is AI ready for inference that is efficient, accurate and fast (i.e., low latency)?
That’s really the question.
Which brings me to my favorite talk of MWC2026, which was by Yuan Yuan, President of Huawei Data Product Storage.

Yuan Yuan, President of Huawei Data Storage Product Line
He asked the question: What is limiting AI adoption in general by business? Especially AI agents?
And his answer (which I agree with) is that the problem is mostly data, memory, and knowledge management.
His argument was that there are three main problems.
- AI has hallucinations. Everyone experiences this every day. It confidently gives you the completely wrong answer. It literally makes up stuff. He argues this is due to gaps between the real world and the foundation models. And it’s mostly a data accuracy problem.
- Using inference can be a poor experience. There can still be a long time to first token. And the inference experience really degrades when you get into long sequences. And when you do multi-turn inference. This is a memory and data processing problem.
- Ai is just not smart enough. It is good at basic tasks but isn’t smart enough to understand advanced or current topics. This is from agents lacking sufficient and accurate context memory.

To make this work, you need:
- Accurate data retrieval. Especially multi-modal data.
- Efficient data retrieval. It needs to be real-time. You need 10,000-level qps (queries per second) and ms-level latency.
- Large-capacity knowledge base. You need vector databases of 10B scale to 100B scale. This is very large vector scale and really matters in RAG.

All of that is in the area of data platforms, knowledge and memory.
How fast can the LLMs access the memory cache? How large is it? And what is the hierarchy between the KV (key value) cache and the other memory (DRAM, SSD)?

The more I think about this, the more I can’t separate data, KV cache / memory and knowledge in practice. The type of inference performance CEOs are looking for requires all of these to work together. Which is what AI Data Platforms (AIDP) do.

That’s what Yuan was talking about and launching at the summit. They have a new packaged solution called the “3+1 solution”.
Huawei’s “3+1” AI Data Platform: Integrating Knowledge, Memory, and KV Cache
This is a data platform that integrates three key technologies:
- Knowledge Generation and Retrieval
The is the tech for knowledge generation and retrieval with high accuracy, and especially for multimodal knowledge. It converts multimodal resources (text, images, and videos) into high-accuracy knowledge through lossless parsing and token-level encoding. They claim it has a retrieval accuracy of +95%.
- Memory Extraction and Recall
With context memory management, models should get smarter with use.
For example, in business data insight scenarios, memory extraction and recall can understand user intent through its personalized memory. It can then break down tasks using episodic memory (or experience-based memory). This memory mechanism should make models smarter with use.
- KV Cache for Inference Acceleration
This is about using historical memory data faster and more efficiently in inference.
For example, in AI customer service scenarios, this technology applies intelligent tiering and management for KV cache to greatly expand the context window and reduce repeated computing. This results in a 90% reduction in time to first token (TTFT), significantly improving the speed of AI responses.
This also includes a Unified Cache Manager (UCM) for managing and scheduling inference memory data throughout the lifecycle. The software manages memory data at three cache levels to intelligently schedule the knowledge base, memory bank, and KV cache.
Here are the details for the 3+1 AIDP.

Ok. Last topic for today.
Final Point: Digital Twins Are Moving From AI-Augmented to Agentic
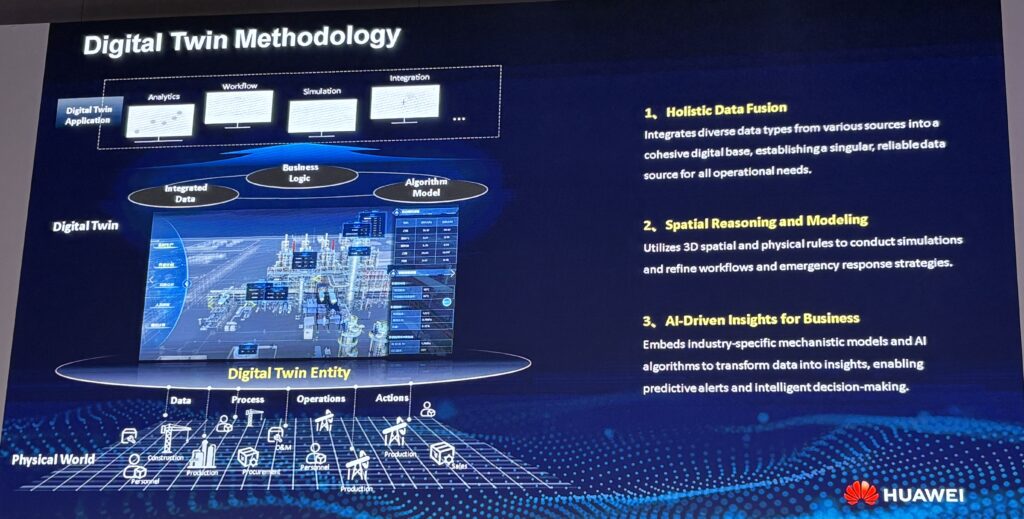
I’m not going to go into this topic in detail. But I think digital twins is an important topic. And here is a cool slide by Xinzhou Cai, from RayChange, about how digital twins have been evolving.
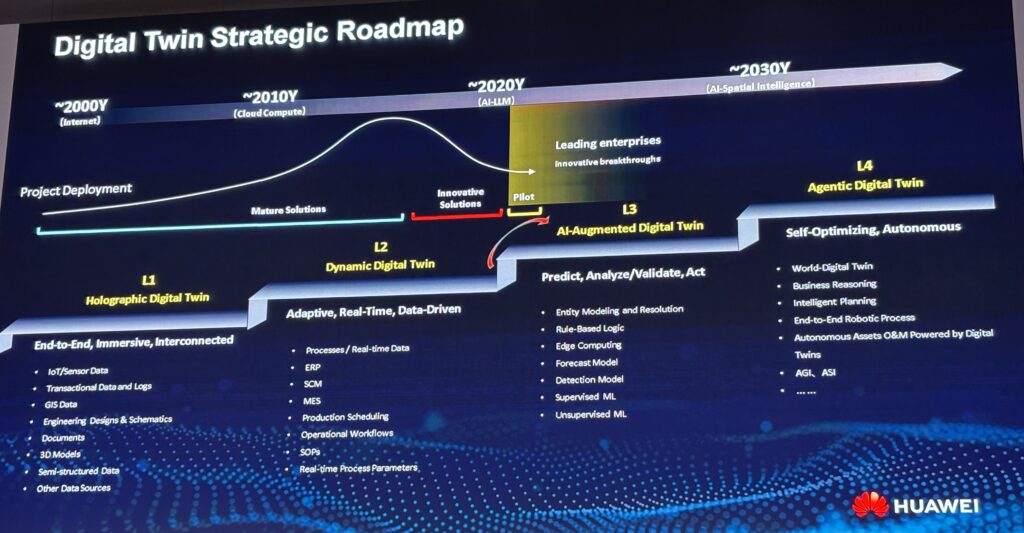
Note current transition from AI-Augmented Digital Twins to Agentic-Digital Twins. That’s what got my attention.
RayChange is a China and Singapore-based company that has been creating digital twins since 2008. Specifically, they are in the business of converting physical assets into digital assets.

And that creates all sorts of interesting options for doing analytics and running simulations. And these twins are now becoming important in training physical AI. And in the emergence of real-world foundation models.
Here is the process RayChange uses to transform physical assets into digital assets. It includes:
- Data management. They have integrated data, holistic data fusion, and business logic. They basically build a cohesive digital base for all operations.
- Visualization management. This is spatial reasoning and modeling. And the modeling of workflows. So, lots of simulations. And maybe world foundation models.
- Lots of apps. Historically, I think RayChange focused on analytics, workflow, simulation, and integration. Basically, turning data into insights. But integrating agents would move this from analytics to action.
Anyways, it’s an interesting topic. And related to the data and inference stuff.
Ok. That’s it for today. In Part 5, I’ll do some business use cases.
Cheers, Jeff
——–
Related articles:
- The Winners and Losers in ChatGPT (Tech Strategy – Daily Article)
- Why ChatGPT and Generative AI Are a Mortal Threat to Disney, Netflix and Most Hollywood Studios (Tech Strategy – Podcast 150)
From the Concept Library, concepts for this article are:
- AI Cloud
- Generative AI and Agents
- AI Infrastructure and Data Centers
- AI Data Platform (AIDP)
From the Company Library, companies for this article are:
- Huawei
——-
I am a consultant and keynote speaker on how to increase digital growth and strengthen digital AI moats.
I am the founder of TechMoat Consulting, a consulting firm specialized in how to increase digital growth and strengthen digital AI moats. Get in touch here.
I write about digital growth and digital AI strategy. With 3 best selling books and +2.9M followers on LinkedIn. You can read my writing at the free email below.
Or read my Moats and Marathons book series, a framework for building and measuring competitive advantages in digital businesses.
This content (articles, podcasts, website info) is not investment, legal or tax advice. The information and opinions from me and any guests may be incorrect. The numbers and information may be wrong. The views expressed may no longer be relevant or accurate. This is not investment advice. Investing is risky. Do your own research.