I’ve given up on “Data Moats” as a real thing.
I’ve definitely given up on data network effects. And to a lesser degree data scale as competitive advantage.
There was a good article written by Martin Casado (and Peter Lauten) of a16z titled:
It’s worth reading. Their main point is that data is just too ephemeral and ubiquitous to create a sustainable moat. It moves around too much. It leaks and can be easily copied (my words, not theirs).
I’ll give you my thinking on this and then my conclusions on data moats. The second part of a previous podcast was about this.
In Part 2, I’ll go through my playbook for data-enabled learning. Which is a big deal.
First Point: Data Network Effects Don’t Exist (Mostly)
The idea of data network effects has been around a long time. It goes:
- Having more customers means you have more data.
- More data means better insights.
- You can use these insights to improve products and experiences.
- That leads to more customers. And therefore, to more data.
- And it repeats.
So, it’s a network effect where having demand side economies of scale means better products. It’s a flywheel at least.
But there are some big gaps in this logic. Especially where more data naturally gets you more product development and better products. That’s a big assumption.
Network effects are about networks. And when there are more people or interactions on these networks, the product itself is naturally better. Like with telephone service or messenger. You can call more people.
The tenuous flywheel just described is really just a standard data-driven personalization and customer improvements. It’s not a network effect. And mostly not even a flywheel. It’s just digital operating basics (specifically DOB2 and DOB3).
–
Ok. So, what about a more automatic process?
Like how people using TikTok naturally personalizes the service. And it happens automatically, with no operational or R&D step. In these cases, data directly improves the product. At the individual level. And at the group level. And larger players will have more access to long-tail content.
That’s closer. But a network effect is about interactions between nodes in a network. That isn’t what is going on here.
The only example I ever see that look like a data network effect are search and Waymo. Where the more users of the service (mapping feedback in Waymo) means a better product. And this is direct interactions between nodes of a network.
That is a maybe for me. But I generally consider this rate of learning.
Overall (like 98% of the time), data network effects just doesn’t exist. It’s mostly about DOB2 and / or rate of learning.
Point 2: What People Are Usually Talking about Is Data Scale Effects. Which Are Weak Advantages.
Question: Does having more data in your corpus makes you better than a rival?
Question: Does having more data flowing through your system make you better than a rival?
Those are both scale arguments for data.
And people often point to Tesla as an example of this. Tesla has more cars driving on the roads, gathering data. And this is making their autonomous driving advance much faster than rivals.
And this is true for now. Tesla has a better service that rivals with smaller scale and miles driven. And AVs have a hive mind. What one knows they all know. This also appears to be true in increasingly intelligent robots.
But these are emerging technologies. And we are talking about early movers who have moved out front. This service advantage will probably not last true long-term. Eventually, most cars will drive pretty good. At least good.
I expect AV capabilities to flatline. Most technology does become ubiquitous. However, robots might have a very long runway for improvements. And the leaders could stay out front for a long time. Like with SpaceX.
Scale advantages usually in mature markets.
There is another big problem in this “data as a scale advantage” argument.
Scale advantages are about quantity and volume. But data is a lot about quality vs. quality. Martin Casado wrote about this in the above linked article.
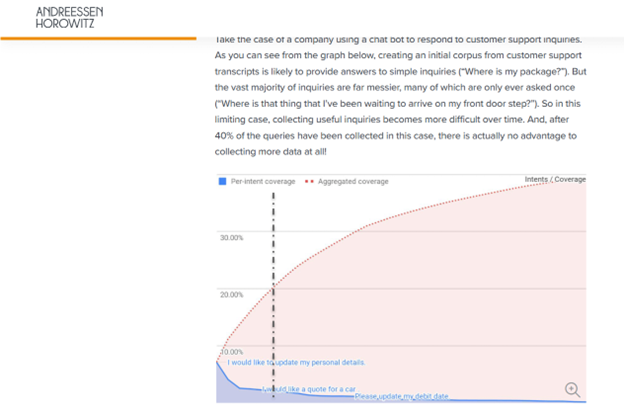
It turns out adding incremental data usually has decreasing incremental value. For example, an automated chat bot in a call center advances quickly when it learns the common questions (“where is my package?”). But as you move to the long tail of questions (“why is the sole coming off my purchased Nike shoes?”), the incremental value decreases. Quality and quantity of data are both important. And quality usually decreases with quantity.
Additionally, incremental value used in GenAI can cost you way more time, effort and money. You need way more data to get the next useful level of value. You need to spend a lot of time to get the system to work on long-tail situations.
Finally, as volume of data increases greatly (which is required for GenAI), it can actually degrade overall quality. You probably have to loosen quality controls to increase quantity. You get more noise and garbage. Lots of things gets worse when you significantly increase the data.
Martin says it’s about identifying a select problem where you can get more data without degrading the result. You want enough but not too much of the data required.
That doesn’t sound like a typical scale advantage.
Here’s a graphic from that a16z article.
Point 3: You Need to Think About the Data Journey and Workflows. Not Just the Data Corpus.
Data is weird. It has no value until it is used. So, you need to think about the process of how it is gathered and used within an activity or enterprise. On an ongoing basis.
Think about:
- How is the data used specifically?
- To improve the product? For training? For ongoing inference? For productivity performance?
- What is the minimum viable corpus for your key data-enabled activities?
- What is ongoing data requirement for your key data-enabled activities?
- What is the value, acquisition cost and ongoing cost for your minimum required data? For incremental data?
- As mentioned, data usually becomes less valuable to add to the corpus. And the next piece of data often increases in cost over time. It becomes harder to find unique data. In network effects, user acquisition costs go down with scale. In data it goes up.
- How fast does the data degrade?
- Data freshness is a big problem. Data goes stale in real world. Streets and traffic change. Temperatures change. Consumer attitudes about things change.
Often it is the minimum viable data corpus that is pointed to as a barrier to entry.
For example, Tesla is way ahead of rivals in training and inference data for AV. And he has mentioned that you have to reach a certain data level before AV starts to work. Which many rivals don’t have.
But data is usually not that firm of a barrier. In theory, you need lots of customers driving your cars to get the data. But people only want to buy the car with the best AV.
In practice, companies can usually bootstrap data to take on incumbents in most situations. Maybe not AV easily. But most places.
- They can do automated data capture from available sources (crawling the web, user data, repurposing other data). It’s pretty easy to get to MVC. And not expensive.
- They can reverse engineer data
- Synthetic data is rapidly emerging.
So yes, this can be a barrier to entry sometimes. But it is mostly about building a data-enabled journey and workflows.
Point 4: Success! Proprietary Data Can Be a Scarce Resource Competitive Advantage.
You need to detail the data process and the segmentation of data.
- What is the segmentation of data by value? Which segments are defensible?
- To what extent is the data itself part of a product? 25%? 75%?
- To what extent do certain data segments fuel and/or improve your products?
That second question is interesting.
Sometimes data can actually be a product in itself. Consulting firms have this. Working with lots of clients gets them best practices and performance indexes. This best practice information can be sold as a product along with their consulting services. Gartner does this all the time. And bigger firms have a larger database of best practices.
This is mostly about proprietary data, which they get from past client work. And that is a competitive advantage.
Note: Some digital services can be added to products, like with maintenance data coming from sensors in tractors. You can sell maintenance monitoring as a data service.
My main point here is that proprietary data can sometimes be a source of competitive advantage. It is a scarce resource (see my below CA list). Especially when it is sold directly as a product.

My Conclusions About Data as a Moat
Ok. Those are my main points. Basically, I think this is one of those situations where we are talking about the wrong concept. Data is just not that useful as a concept. So, most of the derivative thinking is fuzzy. What we really care about is data-enabled learning and adaptation. Which I’ll write about in Part 2.
Here are my conclusions for “data as a moat”:
- Most competitive differences ascribed to data are just early-stage effects.
- Data-enabled learning and activities can be temporary operating advantages for early movers. But this is usually a short-term effect.
- Data can be a barrier to entry.
- Cars need lots of miles to learn to drive and this case is difficult to replicate.
- But this type of data barrier is usually not too hard to overcome.
- Data is almost never a network effect or scale advantage.
- Data network effects are mostly just theory. Maybe Google Search and Waymo.
- There is a real trade-off between data quantity and quality. So, data scale advantages are not obvious moats.
- Data CAN be a scarce resource competitive advantage.
- It can be proprietary data as a corpus. Or as a system for acquiring proprietary data on an ongoing basis.
- Data-enabled learning and adaptation might become a sustainable operating advantage.
- This is the key question I am thinking about. It’s on my SMILE marathon list.

The key question for most management teams is:
- How can you improve your operating performance with data-enabled activities? Especially learning, adaptation and intelligence?
This is where we want to focus. Basically, the Digital Operating Basics.
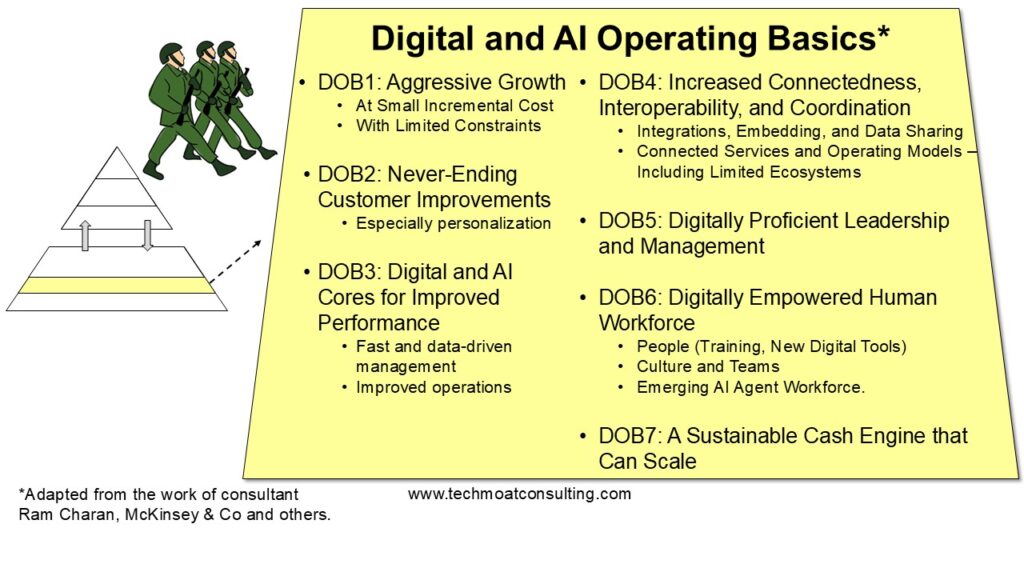
That is what I’ll lay out in Part 2.
Cheers, Jeff
——
Related articles:
- How Alibaba.com Re-Ignited Growth with the Alibaba Management Playbook (Tech Strategy – Podcast 253)
- How Amap Beat Baidu Maps. My Summary of the Alibaba Playbook. (Tech Strategy – Podcast 252)
- Scale Advantages Are Key. But Competitive Advantages Are More Specific and Measurable. (Tech Strategy)
From the Concept Library, concepts for this article are:
- Smile: Rate of Learning and Adaptation
- Competitive Advantage: Scarce or Cornered Resources
From the Company Library, companies for this article are:
- n/a
——-
I am a consultant and keynote speaker on how to increase digital growth and strengthen digital AI moats.
I am the founder of TechMoat Consulting, a consulting firm specialized in how to increase digital growth and strengthen digital AI moats. Get in touch here.
I write about digital growth and digital AI strategy. With 3 best selling books and +2.9M followers on LinkedIn. You can read my writing at the free email below.
Or read my Moats and Marathons book series, a framework for building and measuring competitive advantages in digital businesses.
This content (articles, podcasts, website info) is not investment, legal or tax advice. The information and opinions from me and any guests may be incorrect. The numbers and information may be wrong. The views expressed may no longer be relevant or accurate. This is not investment advice. Investing is risky. Do your own research.